
As information and processing requires have developed, suffering points these types of as functionality and resiliency have necessitated new alternatives. Databases have to have to retain ACID compliance and consistency, supply large availability and large functionality, and handle huge workloads with no turning into a drain on sources. Sharding has presented a answer, but for a lot of organizations sharding has arrived at its limits, because of to its complexity and resource prerequisites. A improved answer is dispersed SQL.
In a dispersed SQL implementation, the databases is dispersed throughout various bodily systems, providing transactions at a globally scalable level. MariaDB System X5, a key launch that consists of updates to each individual part of MariaDB System, gives dispersed SQL and huge scalability by the addition of a new clever storage motor referred to as Xpand. With a shared nothing at all architecture, completely dispersed ACID transactions, and powerful consistency, Xpand lets you to scale to thousands and thousands of transactions per next.
Optimized pluggable clever engines
MariaDB Business Server is architected to use pluggable storage engines (like Xpand) to optimize for distinct workloads from a solitary platform. There is no have to have for specialised databases to handle particular workloads. MariaDB Xpand, our clever motor for dispersed SQL, is the most new addition to our lineup. Xpand provides massively scalable dispersed transactional capabilities to the choices supplied by our other engines. Our other pluggable engines supply optimization for analytical (columnar), browse-major workloads, and produce-major workloads. You can combine and match replicated, dispersed, and columnar tables to optimize each individual databases for your particular prerequisites.
Including MariaDB Xpand enables organization shoppers to get all the positive aspects of dispersed SQL – speed, availability, and scalability – while retaining the MariaDB positive aspects they are accustomed to.
Let’s get a large-level seem at how MariaDB Xpand gives dispersed SQL.
Distributed SQL down to the indexes
Xpand gives dispersed SQL by slicing, replicating, and distributing info throughout nodes. What does this imply? We’ll use a pretty uncomplicated illustration with one desk and three nodes to display the ideas. Not shown in this illustration is that all slices are replicated.
 MariaDB
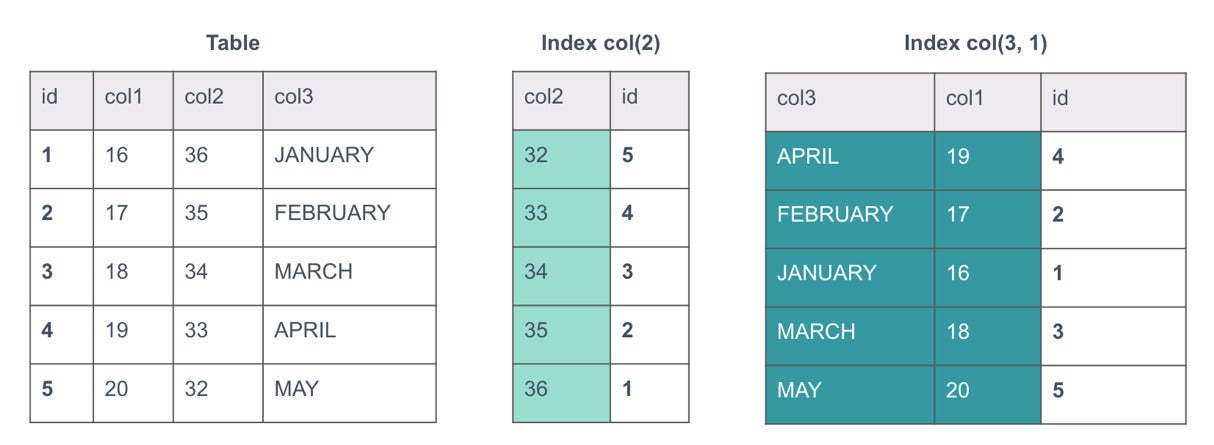
MariaDBDetermine 1. Sample desk with indexes
In Determine 1 higher than, we have a desk with two indexes. The desk has some dates and we have an index on column two, and yet another on columns three and 1. Indexes are in a sense tables on their own. They are subsets of the desk. The major essential is id, the very first index in the desk. That is what will be utilized to hash and spread the desk info out all over the databases.
 MariaDB
MariaDBDetermine two. Xpand slices and distributes info, like indexes, throughout nodes. (Replication is not shown for motives of simplicity. All slices have at minimum two replicas.)
Now we add the idea of slices. Slices are essentially horizontal partitions of the desk. We have five rows in our desk. In Determine two, the desk has been sliced and dispersed. Node #1 has two rows. Node #two has two rows, and Node #three has one row. The objective is to have the info dispersed as evenly as attainable throughout the nodes.
The indexes have also been sliced and dispersed. This is a essential variance between Xpand and other dispersed alternatives. Normally, dispersed databases have nearby indexes, so each individual node has an index of its have info. In Xpand, indexes are dispersed and stored independently of the desk. This removes the have to have to send out a question to all nodes (scatter/get). In the illustration higher than, Node #1 is made up of rows two and four of the desk, and also is made up of indexes for rows 32 and 35 and rows April and March. The desk and the indexes are independently sliced, dispersed, and replicated throughout the nodes.
The question motor makes use of the dispersed indexes to decide the place to uncover the info. It seems up only the index partitions necessary and then sends queries only to the locations the place the necessary info reside. Queries are all dispersed. They are performed concurrently and in parallel. Where they go is dependent entirely on the info and what is necessary to resolve the question.
All slices are replicated at minimum 2 times. For each individual slice, there are replicas residing on other nodes. By default, there will be three copies of that info – the slice and two replicas. Each individual copy will be on a distinctive node, and if you were being operating in various availability zones, those people copies would also be sitting in distinctive availability zones.
Browse and produce managing
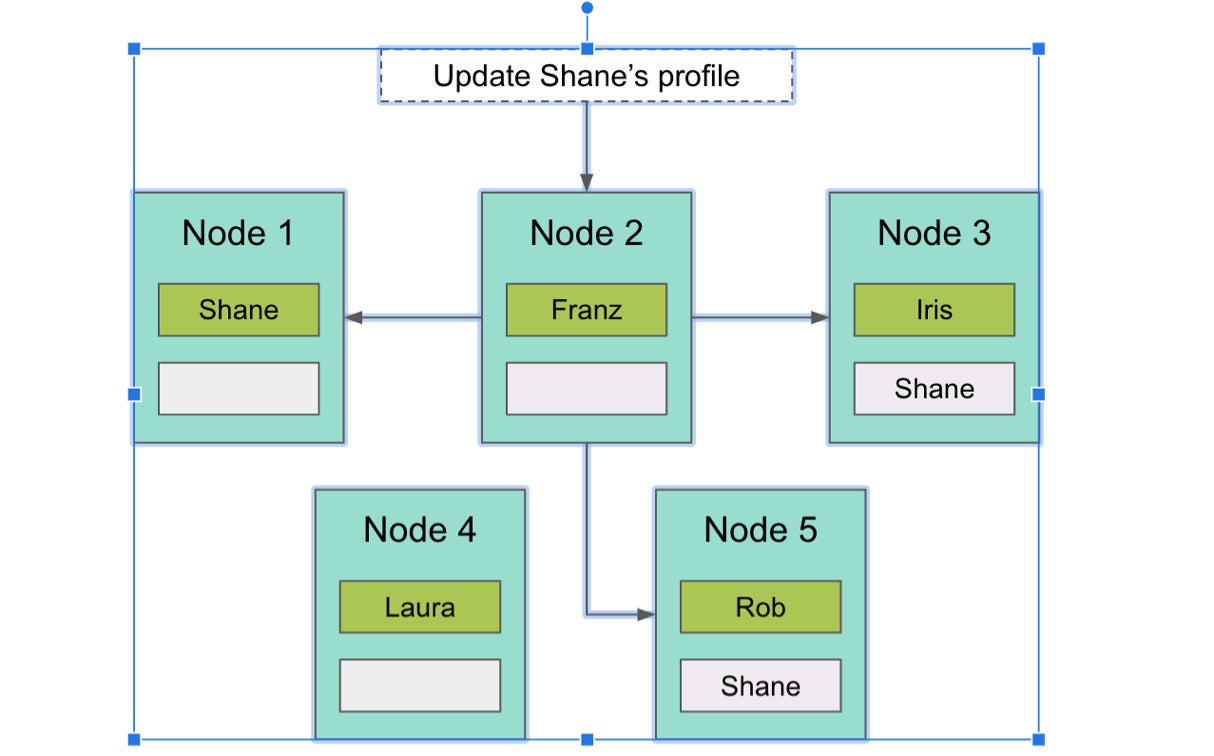
Let’s get yet another illustration. In Determine three, we have five circumstances of MariaDB Business Server with Xpand (nodes). There is a desk to retail store purchaser profiles. The slice with Shane’s profile is on Node #1 with copies on Node #three and Node #five. Queries can arrive in on any node and will be processed in another way dependent on if they are reads or writes.
 MariaDB
MariaDBDetermine three. Writes are processed concurrently to all copies in a dispersed transaction.
Writes are produced to all copies synchronously inside of a dispersed transaction. Any time I update my “Shane” profile since I altered my e mail or I altered my handle, those people writes go to all copies at the exact time in just a transaction. This is what gives powerful consistency.
In Determine three, the UPDATE statement went to Node #two. There is nothing at all on Node #two pertaining to my profile but Node #two is aware of the place my profile is and sends updates to Node #1, Node #three, and Node #five, then commits that transaction and returns back again to the application.
Reads are handled in another way. In the diagram, the slice with my profile on it is on Node #1 with copies on Node #three and Node #five. This would make Node #1 the ranking reproduction. Every single slice has a ranking reproduction, which could be claimed to be the node that “owns” the info. By default, no matter which node a browse arrives in on, it generally goes to the ranking reproduction, so each individual Find that resolves to me will go to Node #1.
Supplying elasticity
Distributed databases like Xpand are constantly shifting and evolving dependent on the info in the application. The rebalancer course of action is dependable for adapting the info distribution to recent requires and retaining the best distribution of slices throughout nodes. There are three general scenarios that simply call for redistribution: adding nodes, eradicating nodes, and preventing uneven workloads or “hot spots.”
For illustration, say we are operating with three nodes but uncover website traffic is escalating and we have to have to scale – we add a fourth node to handle the website traffic. Node #four is vacant when we add it as shown in Determine four. The rebalancer immediately moves slices and replicas to make use of Node #four, as shown in Determine five.
 MariaDB
MariaDBDetermine four. Node four has been extra to handle amplified website traffic. Nodes are vacant when they are extra to the Xpand cluster.
 MariaDB
MariaDBDetermine five. The Xpand rebalancer redistributes slices and replicas to get gain of the amplified capacity.
If Node #four should really fall short, the rebalancer immediately goes to perform once again this time recreating slices from their replicas. No info is misplaced. Replicas are also recreated to replace those people that were being residing on Node #four, so all slices once again have replicas on other nodes to make certain large availability.
 MariaDB
MariaDBDetermine 6. If a node fails, the Xpand rebalancer recreates the slices and the replicas that resided on the unsuccessful node from the reproduction info on the other nodes.
Balancing the workload
In addition to scale out and large availability, the rebalancer mitigates unequal workload distribution – either sizzling spots or underutilization. Even when info is randomly dispersed with a great hash algorithm, sizzling spots can occur. For illustration, it could take place just by probability that the ten solutions on sale this thirty day period take place to be sitting on Node #1. The info is evenly dispersed but the workload is not (Determine seven). In this sort of circumstance, the rebalancer will redistribute slices to stability resource utilization (Determine eight).
 MariaDB
MariaDBDetermine seven. Xpand has evenly dispersed the info but the workload is uneven. Node 1 has a drastically increased workload than the other three nodes.
 MariaDB
MariaDBDetermine eight. Xpand’s rebalancer redistributes info slices to stability the workload throughout nodes.
Scalability, speed, availability, stability
Details and processing requires will continue on to expand. That is a offered. MariaDB Xpand gives a constant, ACID-compliant scaling answer for enterprises with prerequisites that just cannot be achieved with other alternatives like replication and sharding.
Distributed SQL gives scalability, and MariaDB Xpand gives the overall flexibility to pick how substantially scalability you have to have. Distribute one desk or various tables or even your full databases, the alternative is yours. Operationally, capacity is effortlessly adjusted to meet shifting workload needs at any offered time. You by no means have to be in excess of-provisioned.
Xpand also transparently protects against uneven resource utilization, dynamically redistributing info to stability the workload throughout nodes and prevent sizzling spots. For builders, there is no have to have to be concerned about scalability and functionality. Xpand is elastic. Xpand also gives redundancy and large availability. With info sliced, replicated, and dispersed throughout nodes, info is secured and redundancy is taken care of in the celebration of components failure.
And, with MariaDB’s architecture, your dispersed tables will enjoy properly – like cross-motor JOINs – with your other MariaDB tables. Produce the databases answer you have to have by mixing and matching replicated, dispersed, or columnar tables all on a solitary databases on MariaDB System.
Shane Johnson is senior director of product marketing and advertising at MariaDB Corporation. Prior to MariaDB, he led product and technological marketing and advertising at Couchbase. In the earlier, he performed technological roles in growth, architecture, and evangelism at Purple Hat and other organizations. His track record is in Java and dispersed systems.
—
New Tech Discussion board gives a venue to investigate and examine rising organization technology in unparalleled depth and breadth. The range is subjective, based mostly on our decide of the technologies we believe that to be important and of best fascination to InfoWorld audience. InfoWorld does not settle for marketing and advertising collateral for publication and reserves the right to edit all contributed information. Deliver all inquiries to [email protected].
Copyright © 2020 IDG Communications, Inc.



