Massive knowledge seller Cloudera is expanding its portfolio with a series of endeavours aimed at enabling a DataOps design.
Earlier this thirty day period, the business, based mostly in Santa Clara, Calif., announced new and forthcoming attributes for its Cloudera Data Platform, together with Cloudera Data Engineering and Cloudera Data Visualization. The Data Engineering company makes use of Apache Spark for knowledge queries and the Apache Airflow platform for workflow monitoring. The Data Visualization giving is based mostly on technological innovation that comes from Cloudera’s 2019 acquisition of Arcadia Data, which provides reporting and charting operation.
Cloudera Data Engineering is normally readily available now Cloudera Data Visualization is in technical preview.
In accordance to Doug Henschen, an analyst at Constellation Exploration, Cloudera makes a excellent case for the breadth and depth of capabilities it can provide without having the major lifting of knitting together multiple point alternatives, like databases, analytics environments and streaming applications. That explained, he extra that Cloudera also is aware of it still has perform to do on simplifying its platform to lower the expense of possession and maximize worth for clients seeking to assistance knowledge engineering, as very well as knowledge science, knowledge warehousing and operational databases use situations.
David Menninger, a senior vice president and research director at Ventana Exploration, explained Cloudera’s bulletins emphasis on rounding out the platform to present a a single-prevent store for every little thing connected to massive knowledge, from streaming knowledge to knowledge engineering and equipment studying.
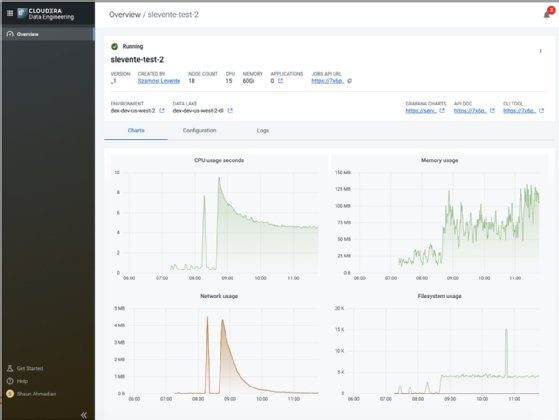
The new Cloudera Data Engineering company is meant to present buyers with visibility and administration into knowledge pipelines and resource utilization.
“The new knowledge engineering capabilities deal with a crucial will need in the market place that numerous many others are contacting DataOps,” Menninger explained. “DataOps addresses the process of automating all the knowledge pipelines that feed analytics to be certain these devices can be put into manufacturing and managed as demands transform.”
DataOps addresses the process of automating all the knowledge pipelines that feed analytics to be certain these devices can be put into manufacturing and managed as demands transform. Dave MenningerSenior vice president and research director, Ventana Exploration
Shaun Ahmadian, senior manager of products administration for knowledge engineering at Cloudera, explained the intention of the new knowledge engineering company is to decouple a good deal of the analytic workflows from the knowledge engineering workflows. Data engineers will now get the applications they especially will need to develop knowledge pipelines and make absolutely sure the suitable knowledge is readily available, he extra.
Raja Aluri, director of engineering at Cloudera, discussed that knowledge engineers usually publish their possess Spark positions for knowledge pipelines, as they want the programmatic ability of Spark to do elaborate knowledge transformations. Spark is practically nothing new for Cloudera, he explained, but what is new is specific tooling in Cloudera Data Engineering that makes it much easier for knowledge engineers to develop and control knowledge pipelines.
“We present an optimized, autoscaling way to operate Spark positions,” Aluri explained.
Bringing Apache Airflow to knowledge engineering
When Spark is a foundational aspect of Cloudera Data Engineering, so, much too, is the Apache Airflow open up source job. Airflow is a workflow orchestration company platform at first made by Airbnb in 2014 and contributed to the Apache Application Foundation in 2016.
Airflow is now a experienced technological innovation, Aluri explained, introducing that there was fascination from the Cloudera purchaser base in earning use of the platform to enable boost knowledge workflows. In accordance to Ahmadian, a essential benefit of Apache Airflow is that it can be prepared in the open up source Python programming language.
“By owning the knowledge pipeline mostly defined as Python code, it draws in a good deal of builders it will enable with any customization that is essential,” Ahmadian explained.